Last Updated: February 2026 | Reading Time: 6 minutes | Author: MacReview Editorial Team
Apple researchers have published a new study exploring how professional designers can improve AI-generated user interfaces through direct feedback. The research builds on earlier work in AI-powered UI generation and suggests a more effective training method than traditional reinforcement learning approaches.
Building on Previous UI Generation Research
Earlier work from Apple’s research team produced UICoder, a family of open-source models focused on generating functional UI code. That initial effort prioritized ensuring AI-generated code could compile correctly and roughly match user prompts, though design quality was not the primary concern. The latest research addresses that gap by focusing specifically on how to train models to produce interfaces that meet professional design standards.
A New Approach to Training AI for Design Work
The new paper, titled “Improving User Interface Generation Models from Designer Feedback,” proposes an alternative to conventional Reinforcement Learning from Human Feedback methods. According to the researchers, standard RLHF techniques do not align well with how designers actually work and fail to capture the detailed reasoning behind design decisions.
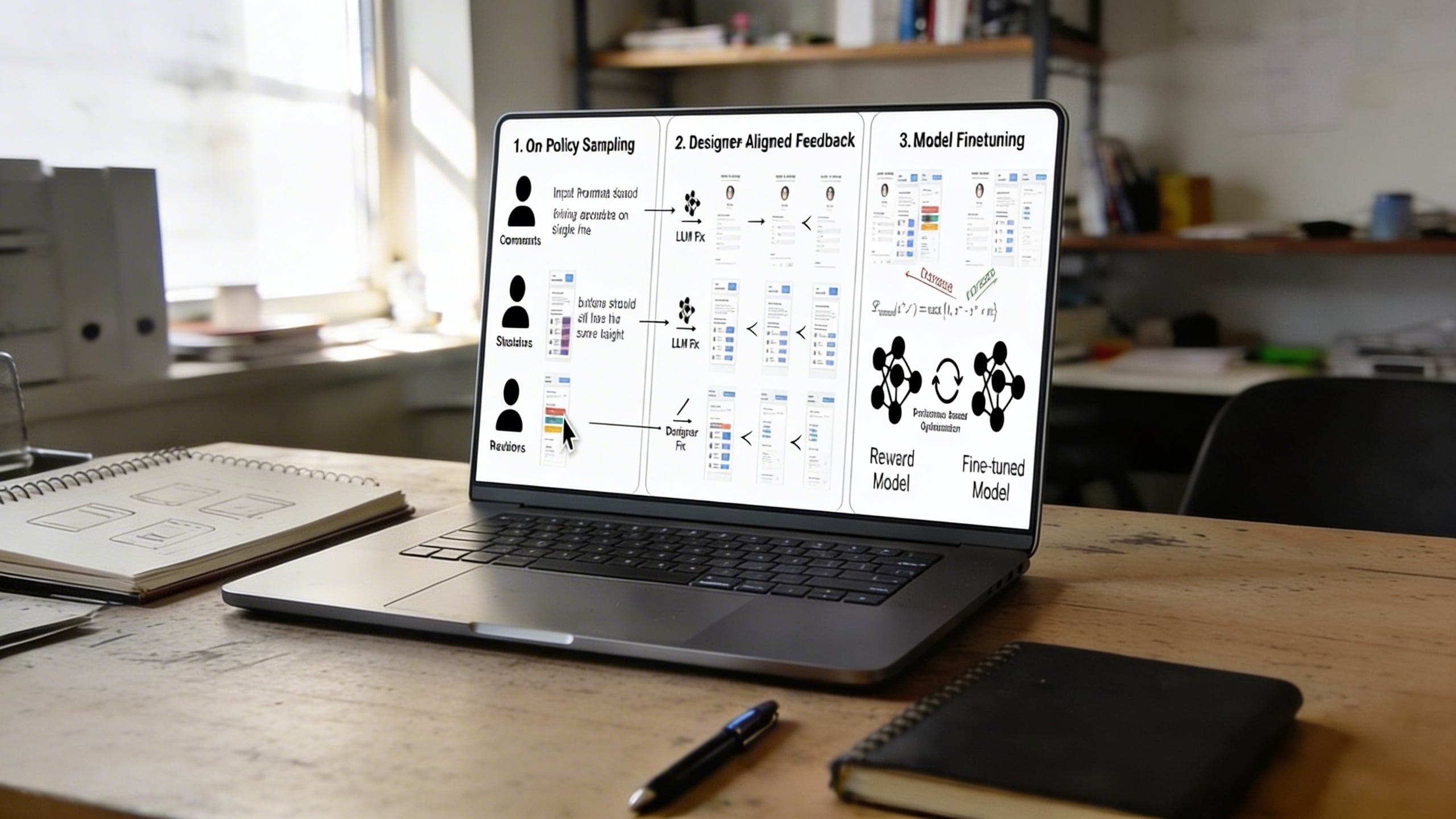
Instead of using simple thumbs-up or ranking systems, the research team had 21 professional designers directly critique and improve AI-generated interfaces. These designers used comments, sketches, and hands-on edits to refine layouts and components. The before-and-after comparisons were then converted into training data used to fine-tune the models.
How Designer Feedback Was Collected
The participating designers had between 2 and over 30 years of professional experience across various specializations including UI/UX design, product design, and service design. They conducted design reviews at frequencies ranging from once every few months to multiple times weekly.
Researchers collected 1,460 annotations from these professionals. These annotations were transformed into paired preference examples that contrasted original AI-generated interfaces with designer-improved versions. This data trained a reward model that could score UI quality based on design judgment rather than simple binary choices.
The Technical Framework
The reward model evaluates two inputs: a rendered UI screenshot and a natural language description of what the interface should accomplish. These inputs produce a numerical score, with higher scores indicating better design quality. The system automatically renders HTML code into screenshots for evaluation.
Apple used Qwen2.5-Coder as the primary base model for UI generation. The research team later tested the designer-trained reward model on smaller and newer Qwen variants to determine how well the approach could generalize across different model sizes and versions.
Performance and Limitations
Models trained on designer-native feedback, particularly those incorporating sketches and direct revisions, produced notably higher-quality interfaces compared to base models and versions trained using conventional ranking data alone.
The study’s best-performing model, a Qwen3-Coder variant fine-tuned with sketch feedback, reportedly outperformed GPT-5 in UI generation tasks. This result came from just 181 sketch annotations, suggesting that high-quality expert feedback can efficiently improve smaller models.
The Subjectivity Challenge
Design quality assessment faces inherent subjectivity challenges. When researchers independently evaluated the same UI pairs that designers had ranked, they agreed with designer choices only 49.2% of the time. However, agreement rates increased significantly when designers provided feedback through sketches (63.6% agreement) or direct edits (76.1% agreement).
This variance suggests that showing specific changes proves more effective than simply choosing between alternatives when communicating design intent. The research team noted that handling subjectivity and multiple valid design solutions remains a significant challenge for human-centered AI training.
Implications for App Development
The research demonstrates that professional design expertise can be effectively captured and transferred to AI models through workflow-native feedback methods. By incorporating sketches and hands-on revisions rather than relying solely on preference rankings, training data better reflects how designers actually think about and improve interfaces.
The framework, while structurally similar to traditional RLHF pipelines, differs in its learning signal source. Rather than collecting simple approval ratings, the system learns from designer actions that naturally occur during the design review process.
FAQ
Q: Are these AI models currently available for developers to use?
A: The research paper describes experimental models and training methods. While the earlier UICoder models are open-source, availability of the designer feedback-trained models has not been announced.
Q: What programming languages or frameworks do these models support?
A: The study mentions HTML code generation and references earlier work with SwiftUI. Specific language support details would depend on the base models and training data used.
Q: How much training data is needed to see improvements?
A: The research showed meaningful improvements with 181 sketch annotations. The full dataset included 1,460 annotations across different feedback types from 21 designers.
MacReview Verdict
Apple’s latest research represents a practical step toward making AI-generated interfaces match professional design standards. By capturing how designers actually critique and improve layouts through sketches and direct edits, the training methodology better reflects real-world design processes than simple ranking systems. The reported performance gains, particularly with smaller models outperforming larger proprietary systems using limited but high-quality feedback, suggest efficiency advantages worth exploring further. However, the documented subjectivity challenges highlight that design quality assessment remains complex. This work contributes meaningful insights into training AI for creative tasks where multiple valid solutions exist and expert judgment involves nuanced considerations beyond binary choices.